Linux 默认调度器 CFS 相关的一些内容。
概念
CFS
CFS(Completely Fair Scheduler)是 Linux 内置(也是目前默认)的一个 内核调度器, 如名字所示,它实现了所谓的“完全公平”调度算法,将 CPU 资源均匀地分配给各进程( 在内核代码中称为“任务”,task)。
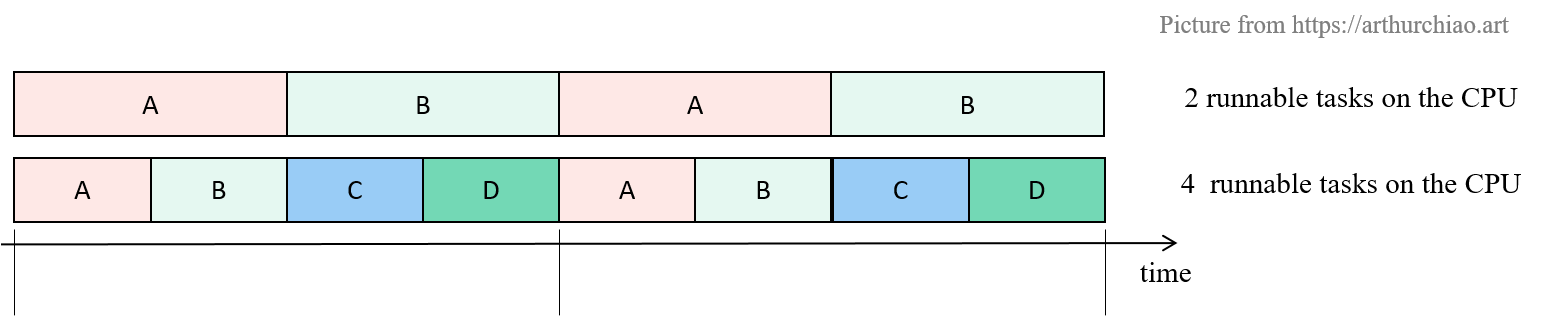
- 两个进程:每个进程会各占 50% CPU 时间;
- 四个进程:每个进程会各占 25% CPU 时间;
支持进程组
进程会组织成进程组(task group)的形式, 用户希望先对进程组分配 CPU 份额,再在每个进程组里面实现公平调度。
比如多用户场景希望对每个用户公平分配 CPU Time
引入了
- 实时任务的组调度(RT group)(SCHED_RT)
- 常规进程的组调度(task group)(SCHED_NORMAL)
CONFIG_RT_GROUP_SCHED 支持对 real-time (SCHED_FIFO 先来先服务 and SCHED_RR 时间片轮转) 任务进行分组 CFS。
实时进程有严格的响应时间限制(Qos 高),要确保这些进程的响应实时性
除实时进程外就是常规进程,没有严格的响应时间限制, 当系统繁忙时,响应延迟就会增加。支持对普通 CFS (SCHED_NORMAL, SCHED_BATCH) 任务进行分组
支持 CPU 限额
CFS 的一些问题
- CFS 不能做到真正完全公平。如果两个 Task,其中一个 Task有很多 sleep/wait 时间, CFS 就会把多余的时间给到第二个 Task,导致第二个 Task 实际使用的时间超过一半。
- 优先级高的进程仍然可能获得更大的时间片,RT 类型任务时,永远比 NORMAL 先执行。优先级可以通过
nice(2)控制。 - 无法设置 CPU 使用上限。CFS 只关注 CPU 平均分配,并不保证 CPU 时间(上下限)。CPU share/quota 只有相对意义,share 大的一定比 share 小的能分到更多 CPU,仅此而已。CPU 限额对按 CPU 时间计费场景很关键,如公有云。
Google 提出了 CFS CPU 带宽控制(CFS bandwidth control)方案。
同时,burst 特性:允许借用前一个进程剩下的带宽。
设计
将真实 CPU 建模为一个“理想、精确的多任务 CPU”
内核为每个 CPU 维护了一个可运行进程的队列(runqueue); CFS 有一个可配置的调度周期 sched_latency;接下来的基本调度过程:
- CFS 根据当前可运行进程的数量 N,计算得到每个进程应该执行的时间 sched_latency/N;
- 依次取出进程执行以上计算出的时间;
- 如果 runqueue 有变化,再重新计算可执行时间。
vruntime
在真实 CPU 上,任意时间只能运行一个任务;为了实现“公平”,CFS 引入了 “virtual runtime”(虚拟运行时间)的概念。
- vruntime 表示进程真正在 CPU 上执行的时间,不包括任何形式的等待时间;
- 机器一般都是多核的,因此 vruntime 是在多个 CPU 上执行时间的累加。
runqueue
是每个 CPU 上的可运行进程队列,之前就已经存在,并不是 CFS 引入的。
time-ordered rbtree
红黑树,查询复杂度:
O(logN)插入复杂度O(logN)
思想:进程 vruntime 最小,说明累计执行时间最少,从“公平”的角度来说,就需要执行它。
CFS 用红黑树来组织这些进程(描述 runqueue),vruntime 为 key,所有 runnable 的进程使用 p->se.vruntime 排序
每次取出最左边的进程(红黑树特性),执行完成后插入越来越右边,这样每个任务都有机会成为最左边的节点, 在一段确定是时间内总得得到 CPU 资源。
同时维护min vruntime 和 max vruntime
min vruntime 用于防止进程饥饿:当一个新的进程被创建或一个等待(阻塞)的进程重新回到就绪状态时,其 vruntime 会被设置为当前所有进程中的最小 vruntime 值。
max vruntime用途是避免 vruntime 的数值超出处理范围:由于 vruntime 是不断累加的,理论上它可能会增长到一个极大的值。max vruntime 作为一个上限,可以防止 vruntime 的溢出(overflow)。
调度策略
RT
SCHED_FIFO
先进先出。
进程在下面的条件下会放弃 CPU:
- 进程在等待,例如 IO 操作。当进程再回到 ready 状态时,它会被放到 runqueue 队尾。
- 进程通过
sched_yieldyield(主动让出) CPU。进程立即进入 runqueue 队尾。
SCHED_RR
在这种调度策略中,runqueue 中的每个进程轮流获得时间片(quantum)。
调度策略:影响的是 runqueue 如何工作,每个进程能获得多少执行时间。
NORMAL
SCHED_NORMAL
历史上叫 SCHED_OTHER,适用于普通任务的调度。
SCHED_BATCH
适合批量任务。不像普通任务那样容易被抢占,因此每个任务运行的时间可以更长,缓存效率更高,但交互性变差。
SCHED_IDLE
这甚至比 nice 19还要弱,但它不是一个真正的空闲计时器调度器,以避免陷入可能导致机器死锁的优先转置问题。
| SCHED_RR | SCHED_NORMAL | |
|---|---|---|
| 调度的进程类型 | 实时进程 | 普通进程 |
| 时间片 | 静态,不依赖系统中的进程数量 | 动态,根据系统中进程的数量会发生变化 |
| 下一个进程的选择 | 从 runqueue 中按 RR 选下一个 | 从红黑树中选 vruntime 最小的一个 |
CPU 配额
给 cpu cgroup 引入了两个新配置项:
cpu.cfs_period_us: 周期(period),每个周期单独计算,周期结束之后状态(quota 等)清零;默认 100mscpu.cfs_quota_us: 在一个周期里的份额(quota),默认 5ms。
最大 1s,最小 1ms:1
2const u64 max_cfs_quota_period = 1 * NSEC_PER_SEC; /* 1s */
const u64 min_cfs_quota_period = 1 * NSEC_PER_MSEC; /* 1ms */
此外还有一个统计输出:
cpu.stat:输出 throttling statistics
后来还引入了一个优化项:- cpu.cfs_burst_us: the maximum accumulated run-time。上一个进程没用完的份额,可以给下一个 CPU 用。
默认值:
1 | cpu.cfs_period_us=100ms |