对于一个编排系统来说,**资源管理**至少需要考虑以下几个方面
- 资源模型的抽象
- 资源的调度
- 资源的限额
k8s 是目前最流行的容器编排系统,那它是如何解决这些问题的呢?
CPU
Kubernetes 会为每个容器都在 CPU Cgroup 的子系统中建立一个控制组,然后把容器中进程写入到这个控制组里。
硬限
这样做对同宿主机的其他容器来说比较安全,因为一旦超过硬限,容器就无法运行,只能等待下一个period;对本容器来说,比较危险。
容器的核数=cpu.cfs_quota_us / cpu.cfs_period_us;
软限
cpu.cfs_quota_us =-1 ,仅设置cpu.shares,即为软限,通过软限可以提升整机的cpu利用率。因为只有当cpu繁忙时,shares才会起作用。并且shares的作用和进程nice值极为相似,都是影响红黑树上节点右移的速度,来间接控制任务获取cpu时间。
cpu.cfs_quota_us、cpu.cfs_period_us
Kubernetes 是通过 CPU cgroup 控制模块中的 cpu.cfs_period_us,cpu.cfs_quota_us 两个配置来实现的。kubernetes 会为这个 container cgroup 配置两条信息:
cpu.cfs_period_us = 100000 (i.e. 100ms)
cpu.cfs_quota_us = quota = (cpu in millicores * 100000) / 1000
容器 CPU 的上限由 cpu.cfs_quota_us 除以 cpu.cfs_period_us 得出的值来决定的。而且,在操作系统里,cpu.cfs_period_us 的值一般是个固定值。
在 cgroup 的 CPU 子系统中,可以通过这两个配置,严格控制这个 cgroup 中的进程对 CPU 的使用量,保证使用的 CPU 资源不会超过 cfs_quota_us/cfs_period_us,也正好就是申请的 limit 值。
对于 cpu 来说,如果没有指定 limit 的话,那么 cfs_quota_us 将会被设置为 -1,即没有限制。
cpu.shares
在 CPU Cgroup 中 cpu.shares == 1024 表示 1 个 CPU 的比例,那么 Request CPU 的值就是 n,给 cpu.shares 的赋值对应就是 n X 1024。
CPU request 是通过 cgroup 中 CPU 子系统中的 cpu.shares 配置来实现的。当你指定了某个容器的 CPU request 值为 x millicores 时,kubernetes 会为这个 container 所在的 cgroup 的 cpu.shares 的值指定为 x * 1024 / 1000。即:
cpu.shares = (cpu in millicores * 1024) / 1000
举个例子,当你的 container 的 CPU request 的值为 1 时,它相当于 1000 millicores,所以此时这个 container 所在的 cgroup 组的 cpu.shares 的值为 1024。
这样做希望达到的终效果就是:即便在极端情况下,即所有在这个物理机上面的 pod 都是 CPU 繁忙型的作业的时候(分配多少 CPU 就会使用多少 CPU),仍旧能够保证这个 container 的能够被分配到 1 个核的 CPU 计算量。其实就是保证这个 container 的对 CPU 资源的低需求。即"Request CPU"就是无论其他容器申请多少 CPU 资源,即使运行时整个节点的 CPU 都被占满的情况下,我的这个容器还是可以保证获得需要的 CPU 数目。
所以
- 在闲的时候,shares 基本上不起作用,只有在 CPU 忙的时候起作用,这是一个优点。
- 由于 shares 是一个绝对值,需要和其它 cgroup 的值进行比较才能得到自己的相对限额,而在一个部署很多容器的机器上,cgroup 的数量是变化的,所以这个限额也是变化的,自己设置了一个高的值,但别人可能设置了一个更高的值,所以这个功能没法精确的控制 CPU 使用率。
概念
| Key | Description |
|---|---|
| cpu.shares | Cgroup 按时分配时间。它适用于所有 CPU (内核) ,默认值为1024。例如,系统中有两个 cgroup,A 和 B。A 的shares value是1024,B 的shares value是512。因此,A 获得66% (1024/(1024 + 512))的 CPU 资源,而 B 获得33% 。 |
| cpu.cfs_period_us | 调度程序的时间配额调整期。该值范围从1毫秒(ms)到1秒(s) ,用于配置当前 cgroup 在设置周期内可以使用的 CPU 时间。 |
| cpu.cfs_quota_us | 计划程序周期中可以占用的时间。该值大于1毫秒。Cfs _ quotus 的值是 -1(默认值) ,这意味着它不受 CPU 时间的限制。 |
| cpu.stat | CPU 统计信息, including nr_periods, nr_throttled, throttled_time |
docker
在docker中可以使用以下参数:
| 参数 | 作用 |
|---|---|
--cpuset-cpus |
限制一个容器可以使用的特定CPU或内核。如果你有一个以上的CPU,一个以逗号分隔的列表或以连字符分隔的容器可以使用的CPU范围。第一个CPU的编号是0。一个有效的值可能是0-3(使用第一、第二、第三和第四个CPU)或1,3(使用第二和第四个CPU)。 |
--cpu-shares |
将这个标志设置为一个大于或小于默认值1024的值,以增加或减少容器的重量,并使它能够获得更大或更小比例的主机CPU周期。这只有在CPU周期受到限制时才会强制执行。当有大量的CPU周期可用时,所有的容器都会根据自己的需要使用尽可能多的CPU。这样一来,这是一个软限制。 |
--cpu-period |
指定CPU CFS调度器的周期,与--cpu-quota一起使用。默认为100000微秒(100毫秒)。大多数用户不改变这个默认值。对于大多数使用情况,--cpu是一个更方便的选择。 |
--cpu-quota |
对容器施加一个CPU CFS配额。容器在节流前每--cpu-period被限制的微秒数。因此,作为有效的上限。对于大多数使用情况,--cpu是一个更方便的选择。 |
--cpus |
指定一个容器可以使用多少可用的CPU资源。例如,如果主机有两个CPU,而你设置了–cpus=“1.5”,那么容器最多保证使用一个半的CPU。这相当于设置--cpu-period="100000"和--cpu-quota="150000"。docker 1.13支持支持,替换cpu-period和cpu-quota |
Memory
1 | pod<UID>/memory.limit_in_bytes = sum(pod.spec.containers.resources.limits[memory]) |
内存的单位在 requests/limits 和在 cgroup 配置文件中都是一样的,所以直接写入 cgroup 内存配置文件。 对于 cgroup v1,
memory.memsw.limit_in_bytes(memory+swap limit)memory.kmem.limit_in_bytes(kernel memory limit)memory.limit_in_bytes(limit of memory)
memory.limit_in_bytes 限制了控制组中所有进程的用户空间内存使用总量,memory.memsw.limit_in_bytes 同时限制了物理内存和交换空间的总和,而 memory.kmem.limit_in_bytes 专门限制了内核内存的使用
QoS
实际的业务场景需要我们能**根据优先级高低区分几种 pod**。例如,
- 高优先级 pod:无论何时,都应该首先保证这种 pod 的资源使用量;
- 低优先级 pod:资源充足时允许运行,资源紧张时优先把这种 pod 赶走,释放出的资源分给中高优先级 pod;
- 中优先级 pod:介于高低优先级之间,看实际的业务场景和需求。
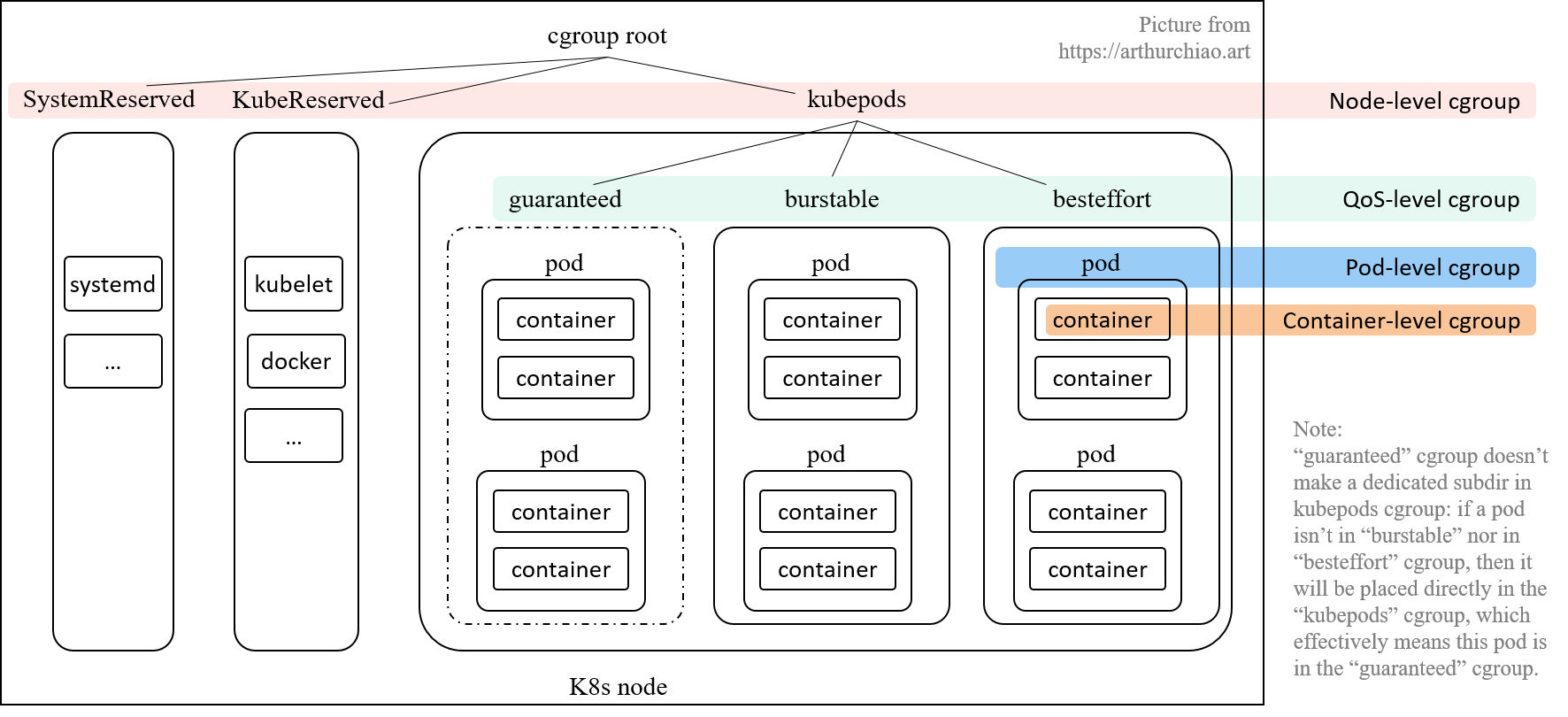
k8s 针对这种需求提供了 cgroups-per-qos 选项:
1 | // pkg/kubelet/apis/config/types.go |
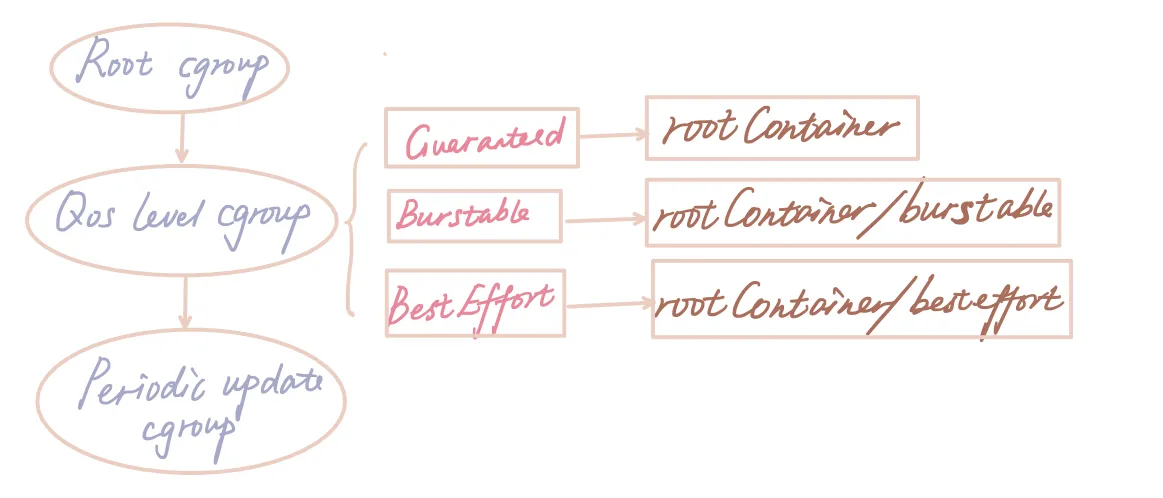
如果设置了 kubelet --cgroups-per-qos=true 参数(默认为 true), 就会将所有 pod 分成三种 QoS,优先级从高到低:Guaranteed > Burstable > BestEffort。 三种 QoS 是根据 requests/limits 的大小关系来定义的:
-
Guaranteed:
requests == limits, requests != 0, 即正常需求 == 最大需求,换言之 spec 要求的资源量必须得到保证,少一点都不行; -
Burstable:
requests < limits, requests != 0, 即正常需求 < 最大需求,资源使用量可以有一定弹性空间; -
BestEffort:
request == limits == 0, 创建 pod 时**不指定 requests/limits** 就等同于设置为 0,kubelet 对这种 pod 将尽力而为;有好处也有坏处:- 好处:node 的资源充足时,这种 pod 能使用的资源量没有限制;
- 坏处:这种 pod 的 QoS 优先级最低,当 node 资源不足时,最先被驱逐。
每个 QoS 对应一个子 cgroup,设置**该 QoS 类型的所有 pods 的总资源限额**, 三个 cgroup 共同构成了 kubepods cgroup。 每个 QoS cgroup 可以认为是一个资源池,每个池子内的 pod 共享资源。
QoS 级别 cgroup 是使用与 Pod 级别 cgroup 相同的 -cgroups-per-qos 参数同时创建的。并且这三种资源计费方法分别对应不同的QoS级别。
此时,每个QoS cgroup可以认为是一个资源池,内部的Pod可以共享资源,并根据优先级合理获取资源。
Kubelet 致力于提高资源效率,默认对 Qos 不设置资源限制,以便 Burstable 和 BestEffort Pod 在需要时可以使用足够的空闲资源。但也要求低优先级的Pod在Guaranteed Pod需要资源时及时释放资源。
对于CPU等可压缩资源,可以通过CPU CFS共享来进行控制,将资源按比例分配给每个QoS Pod,保证在CPU资源有限的情况下,每个Pod都能获得其申请的资源。
参考
k8s 基于 cgroup 的资源限额(capacity enforcement):模型设计与代码实现(2023)
Layer-by-Layer Cgroup in Kubernetes | by Stefanie Lai | Geek Culture | Medium